
Real-time lossless data compression for the FASER experiment

![]()
Real-Time Lossless Data Compression for the FASER Experiment
Introduction
The FASER experiment is an LHC experiment located in a tunnel parallel to the LHC ring. It is considerably smaller and low-budget compared to the titan LHC experiments such as ATLAS and CMS. The experiment seeks to detect new long-lived particles that have travelled half a kilometre from the LHC proton-proton collision site at the centre of the ATLAS experiment, escaping the ATLAS detector undetected. During proton collisions at the LHC, the FASER experiment records up to 1500 events per second using an open-source data acquisition (DAQ) software framework developed at CERN. The DAQ software receives dedicated data fragments from subcomponents on the detector, packs them into a single event and writes completed events to a file. The assigned total storage space for the experiment was, however, quickly met and already resulted in a doubling of the requested storage space. The challenge was to develop a compression engine that would compress data in real-time, introducing minimal latency and performance overheads. The compression engine would also have to decompress events transparently for data reconstruction for physics analysis. <p>
FASER has a trigger-based data acquisition model, and the DAQ software is developed using the DAQling framework.
DAQling is an open-source lightweight C++ software framework that can be used as the core of data acquisition systems of small and medium-sized experiments. It provides a modular system in which custom applications can be plugged in. It also provides the communication layer based on the widespread ZeroMQ messaging library, error logging using ERS, configuration management based on the JSON format, control of distributed applications and extendable operational monitoring with web-based visualization.
DAQling: an open-source data acquisition framework Marco Boretto, Wojciech Brylinski, Giovanna Lehmann Miotto, Enrico Gamberini, Roland Sipos, Viktor Vilhelm Sonesten EPJ Web Conf. 245 01026 (2020) DOI: 10.1051/epjconf/202024501026
You can read more about the FASER TDAQ design in the paper published by the FASER collaboration.
The first part of the project involved the exploration of various open-source lossless compression libraries and the development of a standalone compressor for raw files, which can be used to record performance metrics (such as compression ratio and compression speed) to help determine the best compressor that could be used in the engine. You can read more about the exploration of compression algorithms in this medium blog <p>
After exploration of various algorithms, the next task was to develop a compression engine module that could be integrated into the full FASER DAQ system and can be configured to obtain a compressed file for physics events directly from the acquisition system. The challenge was to design a module that could handle high throughput working at high event rates (as high as 4kHz). The module would publish relevant metrics on the Monitoring dashboard, such as the compression ratio.
| 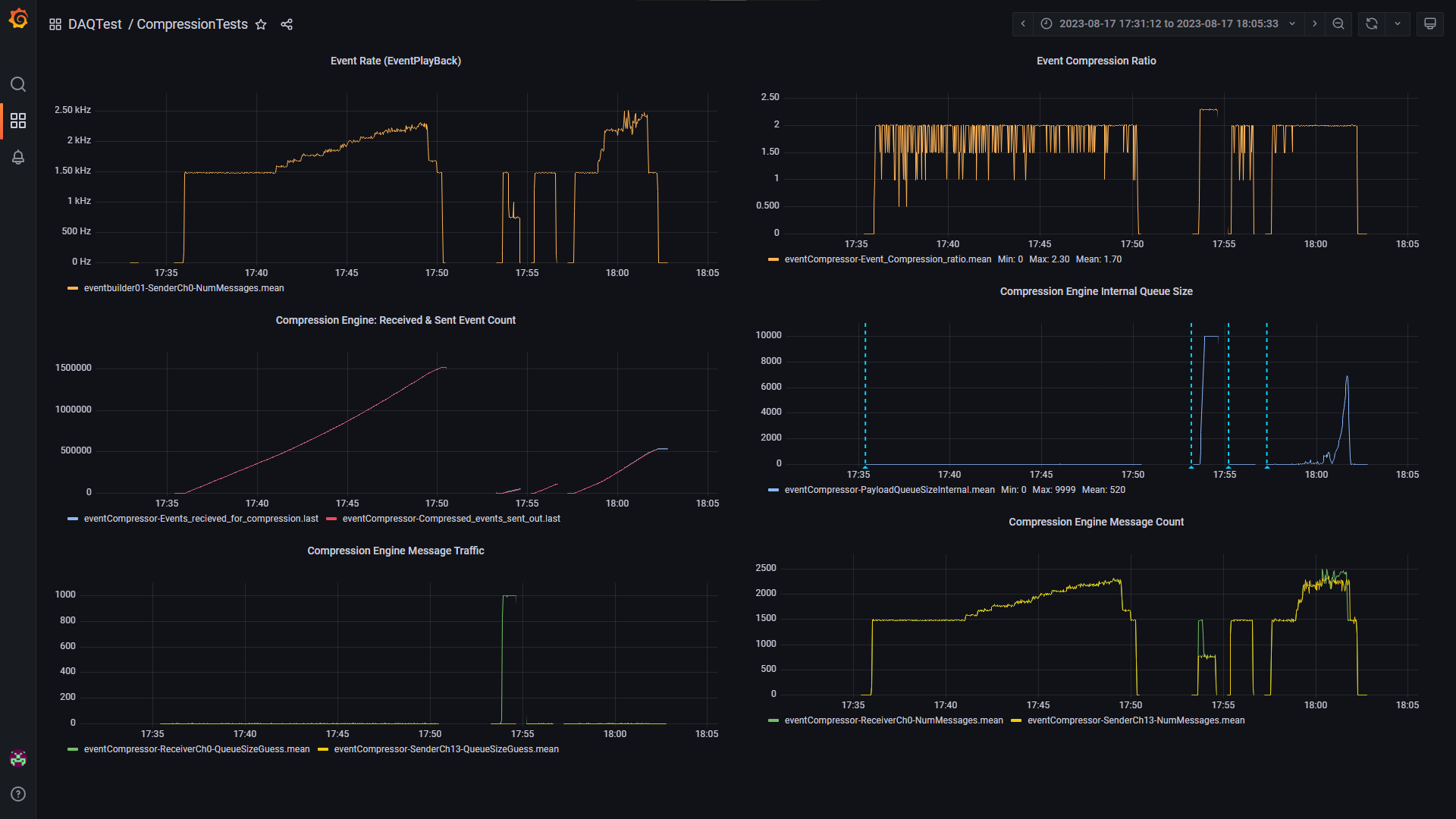 |
|:--:|
| *Fig 1: A Glimpse of The Metrics Dashboard* |
## The Community Bonding Period
Before the coding period, the plan for contributions was roughly chalked out during the community bonding phase. The development setup was finalized during this phase. A Docker-based setup was planned as it helped replicate the production environment and made managing packages and dependencies much more manageable and streamlined. I found some issues with the existing docker image and worked with the mentors to add services like supervisord and reddis to the container configuration. To add support for data compression, additional dev packages were added to aid in building the prototype implementation.
Code for the new Dockerfile can be found here : [master branch on faser-docker](https://gitlab.cern.ch/faser/docker)
It's designed in a non-blocking manner, with an internal buffer to store incoming events and then read events from it to compress and send out. It utilizes multithreading to achieve this by using the producer-consumer queues provided by the Folly library. Essential parts of the design are laid out in the following sections.
```C++
std::array<unsigned int, 2> tids = {threadid++, threadid++};
const auto & [ it, success ] =
m_compressionContexts.emplace(0, std::forward_as_tuple(queue_size, std::move(tids)));
assert(success);
// Start the context's consumer thread.
std::get
Merge Request: [MR #2](https://gitlab.cern.ch/faser/docker/-/merge_requests/2)

## Raw File Compressor
In the first phase of the project, a standalone utility application `eventCompress` [Link to Code](https://gitlab.cern.ch/faser/faser-common/-/blob/compression_app/EventFormats/apps/eventCompress.cxx) was developed which can be used to compress existing raw data files and record performance metrics during the process. It can also do decompression tests and record metrics like decompression speed.
```
Usage: eventCompress [-n nEventsMax -l -d -s -o
Merge Request: [MR #50](https://gitlab.cern.ch/faser/faser-common/-/merge_requests/50)

The logs and the python-based analysis notebooks can be found at [this repo](https://gitlab.cern.ch/faser/online/compression-studies). Please refer to the README for additional information.
### The Best Candidate
| 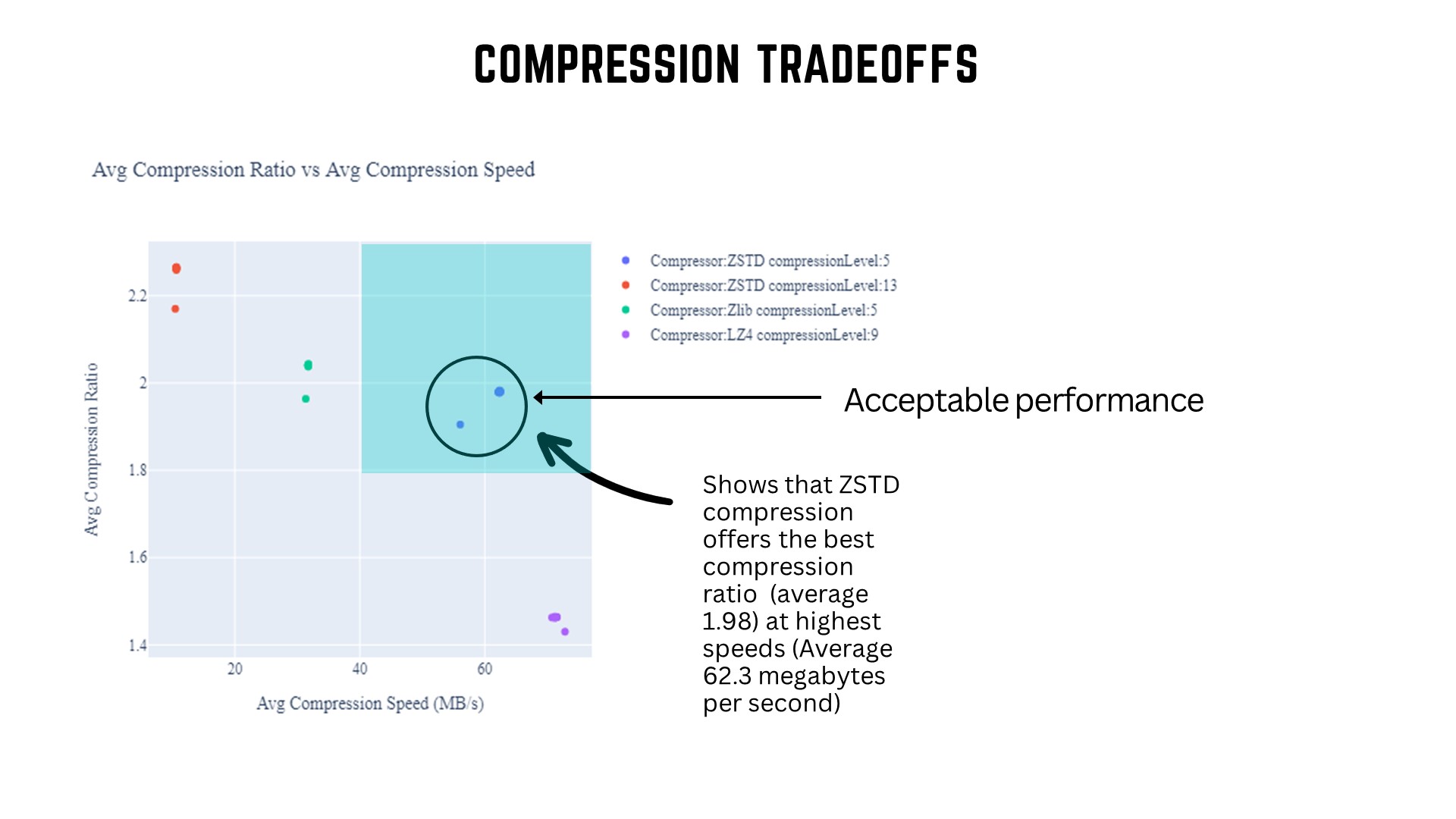 |
|:--:|
| *Fig 2 Average Compression Ratio vs Average Compression Speed* |
The approach for finding the best compressor is described below
- Events were divided into a set of 10 classes based on event size (Class 0 having events of smallest size)
- For each event class, the average compression speed and compression ratio were calculated (for each compressor)
- The resulting points were plotted on a graph, and this helped to visualize the tradeoff. A compression ratio of about 2 (or 50% compression ) and a compression speed of more than 40 MB/s was considered as acceptable performance (as denoted in the diagram above).The compressor configuration offering the highest average compression ratio at the highest compression speed (in the acceptable performance region of the graph) was considered optimal.
After running several experiments with recorded physics data, it was determined that [ZSTD](https://github.com/facebook/zstd) was the best compressor. The __compression levels 3 and 5__ were observed to be the most optimal configuration for implementation.
## The Compression Engine
| 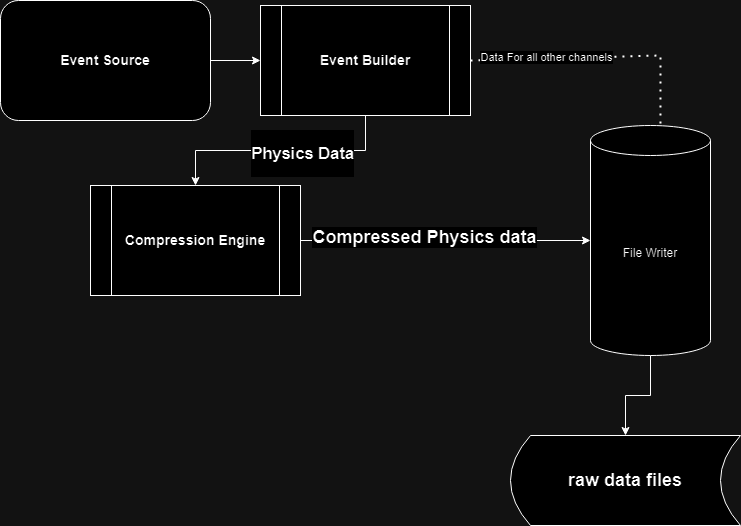 |
|:--:|
| *Fig 3 Schematic Diagram of the Implementation of the Compression Module* |
The final phase of the project was to develop a compression engine module with the DAQling framework that could be added to an existing configuration to compress physics events before they are written out. The EventBuilder module is responsible for collecting the data fragments from event sources (like the tracking detectors) and building events that are sent to the FileWriter Module. The Compression engine sits between these modules, receiving events from the Eventbuilder, compressing them and sending them out to the FileWriter module.
Merge Request: [MR #203](https://gitlab.cern.ch/faser/online/faser-daq/-/merge_requests/203)

### Decompression On-the-Fly
Another essential requirement of the project was to implement support for decompression in a way that would be abstracted from the user. The user should not bother about a file containing compressed events or raw events; all the software used for analysis and reconstruction should be compatible with the compressed files. For this, the loadPayload() method was altered to identify compressed events and decompress events on the fly.
```C++
void loadPayload(const uint8_t *data, size_t datasize) {
std::vector
