HSF Generator Meeting #5, 09 May 2019
Agenda: https://indico.cern.ch/event/813620
Present/Contributors: Andrea Valassi, Simone Amoroso, Efe Yazgan, Qiang Li, Frank Siegert, Alexander Grohsjean, Lukasz Kreczko, Stefan Hoeche, Steve Mrenna, Marek Schoenherr, Markus Schulz, Stephen Jiggins, Josh McFayden
General news
- Efe: Alexander new convener in CMS replacing Efe after August
ATLAS and CMS event generator update
- Simone: slides with an update about generators
- This is an update on the numbers presented at the November workshop.
- These numbers might soon become an ATLAS public document. Eventually also the configurations used to produce them might be shared.
- Slide 3: Powheg plus Herwig faster than Powheg plus Pythia.
- Slide 5: yellow is sherpa with FxFx scale (i.e. the same scale used by MG). This makes sherpa faster by a factor. We plan to exercise this in ATLAS. It may even become the default in sherpa, the authors are looking at that. StefanH: yes we get encouraging results, but still need more tests.
- Qiang: does FxFx affect the negative weight fraction? Simone: did not check. Marek? If anything the negative weight fraction should get better.
- StefanH: note that MG + Pythia for NLO can have MG unweighted, but then when you add Pythia this also gives you Pythia weights, and you have to unweight again. You could store all events and then unweight. There is some similarity to what alpgen does.
- Slide 7: something a bit unrelated to the previous slides, strategies for reducing negative weights in MG aMC@NLO.
- Andrea: rule of thumb for impact of negative weights? Simone/Frank: some rules of thumb plus some refinement. Andrea: please send them to me or put them on the minutes.
- Slide 7: Qiang, is there a similar way to reduce the negative weights in sherpa in the same way as in MG? Stefan: most negative weights come from h events rather than s events, and a folding strategy is not possible. Stefan: have a feeling that going to a full powheg implementation may be a better strategy. Efe: MG are working on something similar to the powheg method, which may be more effective.
- Simone: would be useful if Josh/Andrea ask the MG authors to report when this becomes available.
- Efe and Qiang: updated the numbers in
https://www.overleaf.com/1326158343ftxgrxxcspxg
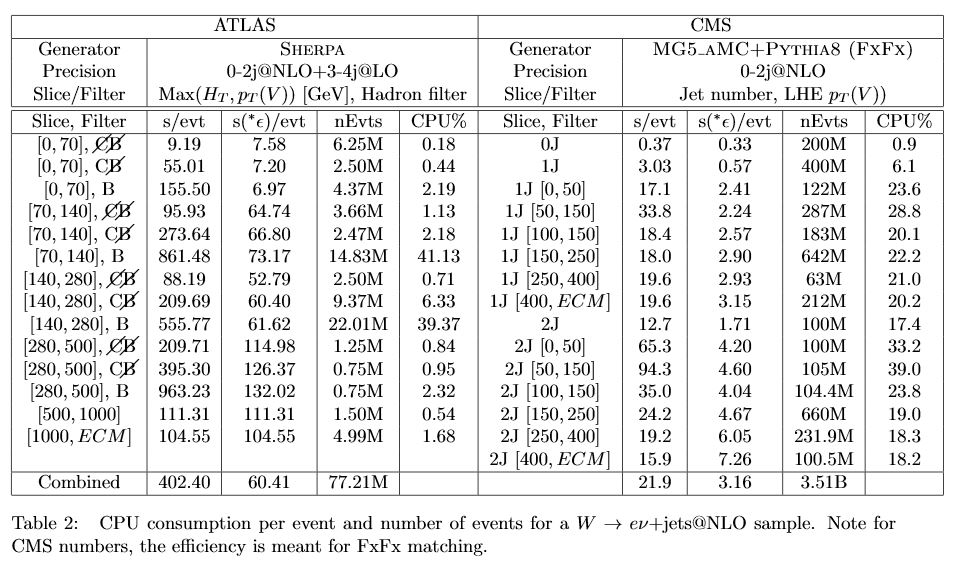
- Table 1 is now updated. Josh: one thing that changed is that
we removed the “Others” section, so the ATLAS number is
reduced and it is more apples to apples.
- Take away: ATLAS 10x slower in generation, 5x slower in detector simulation, 2x slower in reconstruction for the same number of events!
- Alexander: is ATLAS fast sim or full sim? Josh: it’s a mixture of fast sim and full sim.
- Andrea: is this table complete now? Josh: yes, apart from simulation time pointed out by Alexander, this is now pretty complete for generators, nothing missing or nothing too much.
- Table 1 is now updated. Josh: one thing that changed is that
we removed the “Others” section, so the ATLAS number is
reduced and it is more apples to apples.
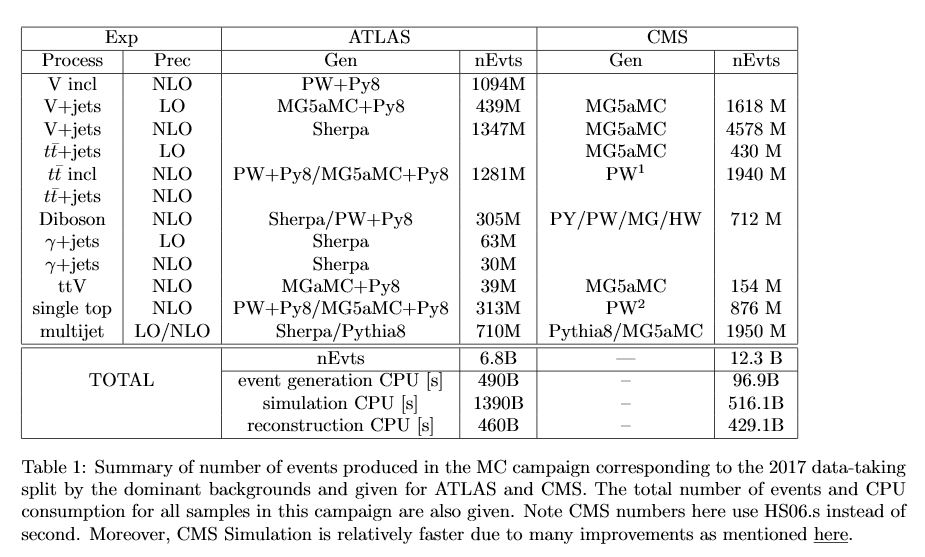
- Qiang: Table 3 is a full apples to apples for LO.
- Efe: here there is a good agreement. There is 30 seconds per event in both cases.
- Frank: however we must make sure we are not biased by filters. For instance there is a difference between the first two columns for timing, still something to understand. In particular, it is becoming apparent that ATLAS makes stricter filters and then produces more expensive, but fewer, events.
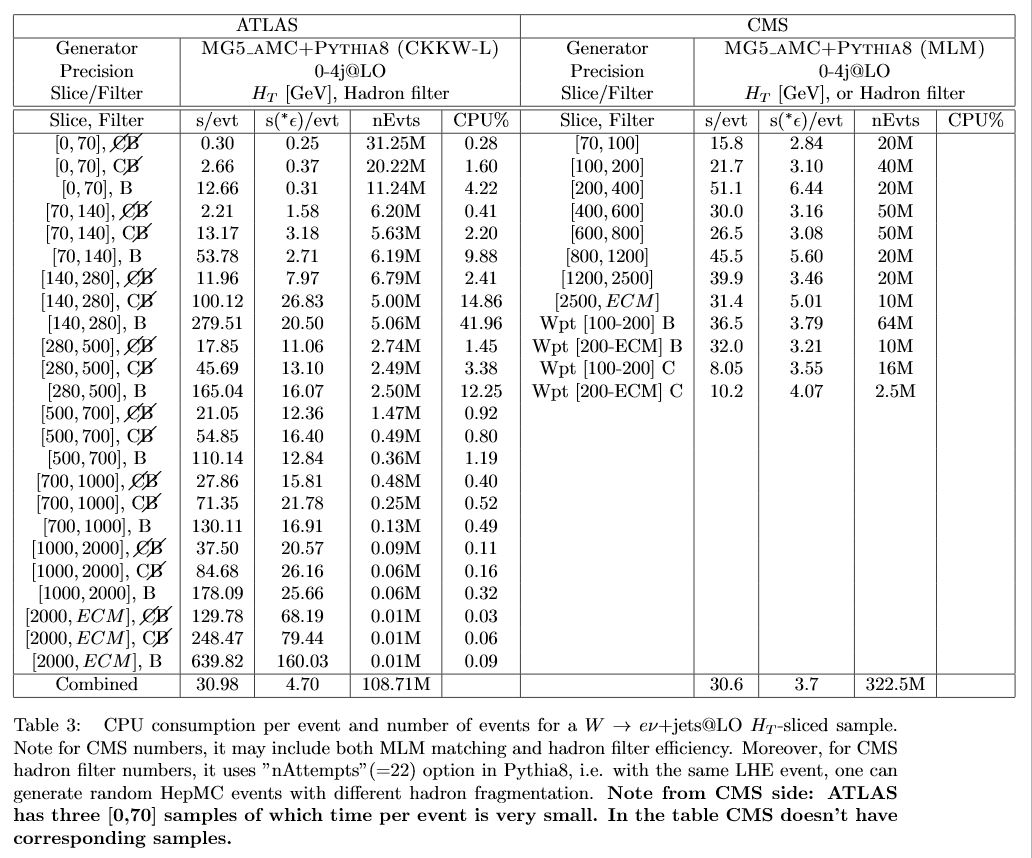
- Table 2 then is apples to apples for NLO. Here sherpa is a factor
20x slower!
- Josh: will write down in text some comments to help interpretation of some details.
- Andrea: totals are 80M events ATLAS and 4B CMS. Ideally it would be nice to get total CPU in Table 1 for each row if possible. Josh: should be easy for ATLAS. Efe; more complex for CMS.
- Andrea: very good progress. We should eventually converge on making this a writeup of the November workshop. Andy Buckley volunteered to help with the writeup of the workshop proceedings, now he has more time free from other commitments
Proposed CHEP 2019 abstract
“Addressing the software and computing challenges of physics event generators”
The HL-LHC physics program will require unprecedented computing resources for simulated collisions and therefore Monte Carlo (MC) event generation. The number of MC events to generate and simulate, which scales as the integrated luminosity of real collisions, is expected to increase at a much faster rate than the available computing resources. The fraction of CPU consumed by MC event generators will also increase dramatically, as the LHC experiments are expected to use primarily fast detector simulation. In addition, the availability and reliance upon higher precision theoretical calculations is also expected to increase, resulting in increased computing resource requirements for MC generation compared to today. Consequently, to ensure physics results are not restricted by a limited number of MC events that can be generated on the available resources, significant optimisation upon the current model is required.
To achieve this, first a detailed analysis of the current computing model for MC event generators is required, followed by optimisation to improve generator software performance. In addition, developing generator software to be able to exploit the evolution of computing architectures in the HL-LHC era, which will likely take the form of accelerator-based High Performance Computing clusters, will be vital. Such architectures are better suited to the smaller code-bases of MC generators rather than the vast code bases of the LHC experiments simulation and reconstruction infrastructures. Finally, more precise projections of the generator-level physics requirements for HL-LHC are also required from theorists and experimentalists.
The HEP Software Foundation has recently created an Event Generators Working Group that aims to bring together MC generator authors, LHC experiment users and software experts to address these issues. The first results of this working group are presented here. This includes a detailed study of the ATLAS and CMS generator usage during Run 2, benchmarking of different MC generator CPU performance, and first studies on using MC generator code on new architectures.
- Andrea: propose to send this abstract to CHEP, with an initial list of authors including WG conveners and those that have so far been most active with presentations (experiment WG convenors and Zach), unless they want to opt-out, and myself as initial candidate speaker. However all WG members can also choose to opt-in and ask to be included as authors if they feel this appropriate. Then we still have time to decide about the actual speaker and even more time for the actual list of authors.
- Efe/Qiang: sounds good.
AOB
- Andrea: would be nice to resume work and discussion on GPUs in
future meetings.
- Simone: Taylor made a presentation on VEGAS for GPUs in an ATLAS presentation, we could ask him to give more details. Andrea: yes, I have also discussed with him his work on alpgen on PowerPC.
- Frank: note this was work from a few years ago, ATLAS is not really using alpgen now. Stefan: true, alpgen less used now, but the techniques Taylor and colleagues had used are still useful. We are now working on an integration of sherpa on HPCs, reusing some of the technicalities that Taylor had used for alpgen. This is using MPI. Even going to many jets, you can cut memory and fit on existing machines, so you can fit in a KNL based HPC.
- Andrea: very good to know this also fits on KNL, but am really more worried about GPUs on HPCs in the future. Stefan: yes we definitely must work on GPUs, anyway KNL based HPCs exist and are there to stay with us for some time.
- Josh: speaking of new topics, we should go back to the question of
how to get more people involved in the coding effort.
- Stephen: agree, getting the grants to do software porting is important, I see this now as a postdoc working on code.